



开源时代是运维类工程师红利时代,也是老一代工程师悲哀时代,老一辈注定很难只精通一门数据库Oracle或者其他技术独善其身。
在云计算时代,我们云计算的类型不同分为了IAAS、PAAS、SAAS,这里面传统IAAS 层面监控可以通过zabbix、nagios、以及小米的openfalcon来实现、但是到PAAS层面后,更多是监控容器以及pod,zabbix虽然可以通过一些python插件来完成,但是远不如Prometheus做好。
一、认识Prometheus
Prometheus是一个开源系统监控和警报工具包,最初是在 SoundCloud构建的Prometheus 于 2016 年加入了 CNCF,成为了继 Kubernetes 之后的第二个托管项目。在云原生监控领域属于绕不开的必须要掌握的技能
Prometheus 有以下特点:
- 通过指标名(metric name)和 KV 结构,使用时序数据(time series data)表达的多维度数据模型
- PromQL是用于查询和分析Prometheus监控数据的查询语言。它是一种专门为时间序列数据设计的语言,用于从Prometheus TSDB中检索、过滤、聚合和分析时间序列数据。
- 对分布式存储没有依赖;单服务器节点即可自治
- 通过使用基于 HTTP 的拉模式 (pull model) 进行时序数据采集
- 通过中间网关 ( gateway) 以支持推送时序数据
- 通过服务发现或静态配置,来发现监控的目标
- 支持多图和仪表盘模式
想要搞清楚它特性需要以下关键词:时间序列数据库、多维数据模型。
1.1 时间序列数据
什么是时间序列:按照时间顺序记录系统、设备状态变化的数据被叫做时序数据
应用场景:
- 无人驾驶车辆运行中记录的速度、方式、旁边的物体的距离等等。每时每刻都要将数据记录下来分析。
- 传统证券行业的实时交易数据
- 服务器的实时监控数据
时间序列数据库是针对时间戳或时间序列数据优化的数据库,例如传统的MySQL只是在处理时间序列时候性能比不上专用的。
高效的压缩算法,节省存储空间,有效降低IO
总之时间序列数据库是专门为处理带时间戳的指标和事件或测量而开发的产品。
MySQL 与Prometheus-PromQL的区别
prometheus 官网链接:https://prometheus.io/docs/
1.3 多维数据模型
多维数据模型是指在时间序列数据库中,数据可以通过多个标签(或维度)来描述。这允许对数据进行更细粒度的分类、筛选和聚合。
Prometheus中的多维数据模型允许使用多维查询,以便更灵活地选择、过滤和聚合数据。
1.3 prometheus
以下是prometheus 官方架构图
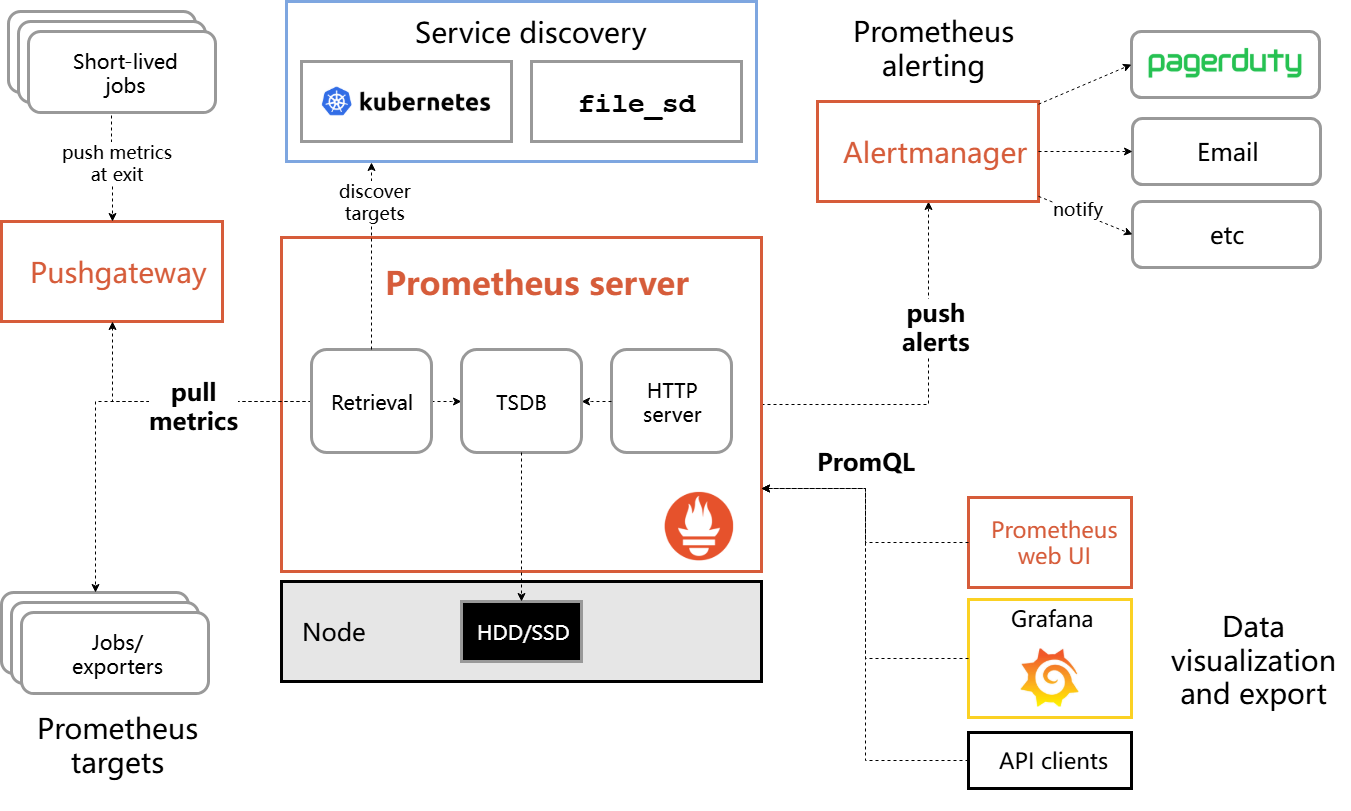
Prometheus 采样数据有两种方式,一种是直接采样仪表化任务(instrumenting job),另一种通过中介 push gateway 来采样短时任务。
Prometheus 在本地存储所有采样的样本,同时基于这些数据,执行规则(rules)用以从已存数据上聚合、记录新的时序数据,或用以发送报警。Grafana或其他的 API consumers 可以可视化这些收集的数据。
- push geteway:数据收集的代理服务器,类似于zabbix proxy
- Prometheus tagets:静态收集的目标服务数据
- Prometheus server:主服务,接收外部的http请求、收集、存储、查询数据(Retrieval 数据抓取,存储在tsdb:轻量时序数据库)
- server discovery:动态发现服务
- Alertmanager:管理告警的插件
- PromQL:Prometheus的对应的时序数据库,通过web通过查询实现数据可视化
Prometheus 的核心是Prometheus server,理解以上的架构图可以通过以下的server 核心图来理解。

二、部署Prometheus Operator
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。
kube-prometheus/kube-prometheus-stack
最简单的方法是将 Prometheus Operator 作为 kube-prometheus 的一部分进行部署。kube-prometheus 部署了 Prometheus Operator,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- ...
2.1 helm 安装 prometheus-operator
需要在集群中安装helm ,helm 安装
1.新建ns monitoring,并添加helm repo源
[root@k8s-master01 ~]kubectl create ns monitoring
namespace/monitoring created
[root@k8s-master01 ~]helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
[root@k8s-master01 ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "prometheus-community" chart repository
...Successfully got an update from the "azure" chart repository
...Successfully got an update from the "stable" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈2.查看可以用的 kube-prometheus-stack 包
[root@k8s-master01 ~]# helm search repo kube-prometheus-stack
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/kube-prometheus-stack 54.0.1 v0.69.1 kube-prometheus-stack collects Kubernetes manif...
[root@k8s-master01 ~]# helm install prometheus prometheus-community/kube-prometheus-stack -n monitoring
Error: INSTALLATION FAILED: failed to download "prometheus-community/kube-prometheus-stack"本来计划使用helm 一键安装但是由于网络问题看样子是无法安装kube-prometheus stack
2.2 kube-prometheus stack 版本对照表
Kubernetes 1.21 以前的版本
详细的对应的kube-prometheus请参照github:https://github.com/prometheus-operator/kube-prometheus
| kube-prometheus stack | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 |
|---|---|---|---|---|
release-0.5 |
✔ | ✗ | ✗ | ✗ |
release-0.6 |
✗ | ✔ | ✗ | ✗ |
release-0.7 |
✗ | ✔ | ✔ | ✗ |
release-0.8 |
✗ | ✗ | ✔ | ✔ |
release-0.9 |
✗ | ✗ | ✗ | ✔ |
Kubernetes 1.22 以后的版本
| kube-prometheus stack | Kubernetes 1.22 | Kubernetes 1.23 | Kubernetes 1.24 | Kubernetes 1.25 | Kubernetes 1.26 | Kubernetes 1.27 | Kubernetes 1.28 |
|---|---|---|---|---|---|---|---|
release-0.9 |
✔ | ✗ | ✗ | ✗ | ✗ | ||
release-0.10 |
✔ | ✔ | ✗ | ✗ | x | x | x |
release-0.11 |
✗ | ✔ | ✔ | ✗ | x | x | x |
release-0.12 |
✗ | ✗ | ✔ | ✔ | x | x | x |
release-0.13 |
✗ | ✗ | ✗ | x | ✔ | ✔ | ✔ |
main |
✗ | ✗ | ✗ | x | x | ✔ | ✔ |
我这边使用的Kubernetes 版本是v1.22.8 ,使用release-0.9和release-0.10版本
2.3 安装 prometheus-operator(拉包方式)
- 从选择从github上拉取release-0.10版本的包
[root@k8s-master01 ~]# git clone https://github.com/prometheus-operator/kube-prometheus.git -b release-0.10
Cloning into 'kube-prometheus'...
remote: Enumerating objects: 18880, done.
remote: Counting objects: 100% (5483/5483), done.
remote: Compressing objects: 100% (392/392), done.
remote: Total 18880 (delta 5274), reused 5126 (delta 5079), pack-reused 13397
Receiving objects: 100% (18880/18880), 9.84 MiB | 1.22 MiB/s, done.
Resolving deltas: 100% (12719/12719), done.2.将kube-prometheus里的包替换为国内的,测试过不替换也是可以安装
cd kube-prometheus
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' `grep "quay.io" -rl *`查看镜像
find ./manifests -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'
1:quay.io/prometheus/prometheus:v2.32.1
2:quay.io/prometheus-operator/prometheus-operator:v0.53.1
3:quay.io/prometheus/node-exporter:v1.3.1
4:quay.io/prometheus/blackbox-exporter:v0.19.0
5:quay.io/prometheus/alertmanager:v0.23.0
6:quay.io/brancz/kube-rbac-proxy:v0.11.0
7:k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
8:k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
9:jimmidyson/configmap-reload:v0.5.0
10:grafana/grafana:8.3.3- 替换镜像路径
sed -i s#k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0# /kube-state-metrics:v2.3.0#g ./manifests/kubeStateMetrics-deployment.yaml
sed -i s#k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1#v5cn/prometheus-adapter:v0.9.1#g ./manifests/prometheusAdapter-deployment.yaml- 安装Prometheus Operator
kubectl apply --server-side -f manifests/setup
kubectl apply -f manifests/- 查看安装情况
[root@k8s-master01 ~]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 15h
alertmanager-main-1 2/2 Running 0 15h
alertmanager-main-2 2/2 Running 0 15h
blackbox-exporter-6798fb5bb4-cn7qf 3/3 Running 0 15h
grafana-78d8cfccff-dfvrf 1/1 Running 0 15h
kube-state-metrics-5dc5df94f4-bt7kz 3/3 Running 0 14h
node-exporter-h2652 2/2 Running 0 15h
node-exporter-vgh6l 2/2 Running 0 15h
prometheus-adapter-57fc6d77-4wjbq 1/1 Running 0 15h
prometheus-adapter-57fc6d77-l8nhd 1/1 Running 0 15h
prometheus-k8s-0 2/2 Running 0 15h
prometheus-k8s-1 2/2 Running 0 15h
prometheus-operator-7ddc6877d5-tzh6w 2/2 Running 0 15h
[root@k8s-master01 ~]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.106.113.165 <none> 9093/TCP,8080/TCP 15h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 15h
blackbox-exporter ClusterIP 10.109.47.55 <none> 9115/TCP,19115/TCP 15h
grafana ClusterIP 10.99.235.171 <none> 3000/TCP 15h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 15h
node-exporter ClusterIP None <none> 9100/TCP 15h
prometheus-adapter ClusterIP 10.100.17.180 <none> 443/TCP 15h
prometheus-k8s ClusterIP 10.100.34.182 <none> 9090/TCP,8080/TCP 15h
prometheus-operated ClusterIP None <none> 9090/TCP 15h
prometheus-operator ClusterIP None <none> 8443/TCP 15h- 暴露prometheus、grafana、alertmanager服务(将ClusterIP修改为NodePort)
可以根据需求,通过ingress 对外暴露或者使用NodePort
#1、prometheus
kubectl patch svc/prometheus-k8s -n monitoring --patch '{"spec": {"type":"NodePort"}}'
#2、grafana
kubectl patch svc/grafana -n monitoring --patch '{"spec": {"type":"NodePort"}}'
#3、alertmanager
kubectl patch svc/alertmanager-main -n monitoring --patch '{"spec": {"type":"NodePort"}}'
######查看service暴露的NodePort端口
[root@k8s-master01 ~]# kubectl get svc -n monitoring |grep NodePort
alertmanager-main NodePort 10.106.113.165 <none> 9093:32308/TCP,8080:31549/TCP 16h
grafana NodePort 10.99.235.171 <none> 3000:30500/TCP 16h
prometheus-k8s NodePort 10.100.34.182 <none> 9090:30090/TCP,8080:32095/TCP 16h- 查看登录密码
grafana默认用户名密码 : admin/admin (Grafana@123)

访问prometheus-k8s 的url 查看发现kube-controller-manager , kube-schedule ,etcd

到这里prometheus-operator 算是安装完成了
三、配置 Prometheus
安装完成prometheus-operator后,默认会出现以下报错:Watchdog、KubeControllerManagerDown、KubeSchedulerDown
其中 Watchdog 是一个正常的报警,这个告警的作用是:如果alermanger或者prometheus本身挂掉了就发不出告警了,因此一般会采用另一个监控来监控prometheus,或者自定义一个持续不断的告警通知,哪一天这个告警通知不发了,说明监控出现问题了。prometheus operator 已经考虑了这一点,本身携带一个watchdog,作为对自身的监控。
KubeControllerManagerDown,KubeSchedulerDown
检查是否有kube-controller-manager和kube-scheduler的服务
[root@k8s-master01 kube-prometheus-work]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 4h5m
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 3h49m
metrics-server ClusterIP 10.99.254.254 <none> 443/TCP 3h38m创建之前需查询ServiceMonitor 和endpoints 查看所有标签


kube-controller-manager和kube-scheduler 的服务的标签一定要和ServiceMonitor 中有一样的,这样可以关联
以下是kube-controller-manager和kube-scheduler 的service文件
[root@k8s-master01 kube-prometheus-work]# cat kube-controller-manager-svc.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
ports:
- name: https-metrics
port: 10257
selector:
component: kube-controller-manager
[root@k8s-master01 kube-prometheus-work]# cat kube-scheduler-svc.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
ports:
- name: https-metrics
port: 10259
selector:
component: kube-scheduler安装上面的两个svc文件
kubectl apply -f kube-controller-manager-svc.yam
kubectl apply -f kube-scheduler-svc.yaml因为 kube-controller-manager 启动的时候默认绑定的是 127.0.0.1 地址,所以要通过 IP 地址去访问就被拒绝了,所以需要将 --bind-address=127.0.0.1 更改为 --bind-address=0.0.0.0 ,更改后 kube-scheduler 会自动重启,重启完成后再去查看 Prometheus 上面的采集目标就正常了,网上很多说还需要改kube-scheduler.yaml,测试不该改监控就已经恢复了
sed -i 's/bind-address=127.0.0.1/bind-address=0.0.0.0/g' /etc/kubernetes/manifests/kube-controller-manager.yaml补充1:如果kube-scheduler和kube-controller-manager 如果缺少标签,可以通过以下命令来关联
kubectl label service -n kube-system kube-scheduler app.kubernetes.io/name=kube-scheduler
kubectl label service -n kube-system kube-controller-manager app.kubernetes.io/name=kube-controller-manager补充2:如果要清理/卸载 Prometheus-Operator,可以直接删除对应的资源清单即可:
# kubectl delete -f manifests
# kubectl delete -f manifests/setup四、grafana 模板选择
推荐以下两个Dashboard,显示内容如下:
4.1 grafana Dashboard 推荐

选取原因内容丰富,几乎涵盖日常90% 需要注意的内容


五、案例 Prometheus 添加告警
5.1 添加etcd 告警
通过自动发现的方式监控etcd
创建etcd Prometheus 监控所需内容:Serivce 和 ServiceMonitor。
[root@k8s-master01 kube-prometheus-work]# cat etcd-svc.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: etcd
labels:
app.kubernetes.io/name: etcd
spec:
ports:
- name: https-metrics
port: 2379
selector:
component: etcd
tier: control-planeetcd 为了安全必须要用证书才能访问,将 etcd 证书导入到 Secret 中
kubectl create secret generic etcd-certs \
-n monitoring \
--from-file=/etc/kubernetes/pki/etcd/ca.crt \
--from-file=/etc/kubernetes/pki/apiserver-etcd-client.crt \
--from-file=/etc/kubernetes/pki/apiserver-etcd-client.key创建 etcd 的 Prometheus 监控配置
[root@k8s-master01 kube-prometheus-work]# cat etcd-ServiceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app.kubernetes.io/name: etcd
app.kubernetes.io/part-of: kube-prometheus
spec:
endpoints:
- interval: 15s
port: https-metrics # 端口名称
scheme: https
tlsConfig: # etcd 证书,这是在 prometheus 里面的路径
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/apiserver-etcd-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/apiserver-etcd-client.key
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector: # 标签匹配 etcd Service 所在的命名空间
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: etcd # 标签匹配 etcd Service配置 etcd Service 和 etcd ServiceMonitor 后还没完,还需要将 etcd 证书挂载到 Prometheus 里。
编辑 manifests/prometheus-prometheus.yaml,加入前面创建的 Secret。或者直接用命令 kubectl edit prometheuses k8s -n monitoring。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: k8s
namespace: monitoring
spec:
secrets: # etcd 证书的 Secret
- etcd-certs打开 Prometheus Web 界面,这时候应该能看到 etcd 的 targets 了

到这里 kube-apiserver、etcd、kube-controller-manager、kube-scheduler、credns、这些系统组件都已经监控已经覆盖80%,剩余监控就是网络插件cni具体方案的监控,以及ingress-controller,kube-proxy,以及对node 特殊定制化监控,pv的监控以及pod和应用的具体监控,以上应该可以覆盖所有需要做的.
六、AlertManager配置报警
prometheus 警报分为两部分。Prometheus 服务器中的警报规则将警报发送到警报管理器。然后,Alertmanager 管理这些警报,包括沉默、抑制、聚合以及通过电子邮件、待命通知系统和聊天平台等方法发送通知。
Alertmanager是由Prometheus社区开发的一个独立组件,用于处理Prometheus监控系统生成的警报(Alerts)。它的主要作用是管理和路由警报通知,确保警报以可靠的方式发送到相应的接收者,并进行去重和聚合等操作
6.1 短信告警
[root@k8s-master01 kube-prometheus]# cat manifests/alertmanager-secret.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.23.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
smtp_from: "erice_jia@163.com"
smtp_smarthost: "smtp.163.com:465"
smtp_auth_username: "erice_jia@163.com"
smtp_auth_password: "VIKMGSHHHMCPOKNP"
smtp_require_tls: false
smtp_hello: "163.com"
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
"receivers":
- "name": "Default"
email_configs:
- to : "29525939@qq.com"
send_resolved: true
- "name": "Watchdog"
email_configs:
- to : "243645649@qq.com"
send_resolved: true
- "name": "Critical"
email_configs:
- to : "243645649@qq.com"
send_resolved: true
"route":
"group_by":
- "namespace"
- "job"
- "alertname"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "Watchdog"
- "matchers":
- "severity = critical"
"receiver": "Critical"
type: Opaque6.2 自定义报警规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
name: demo
namespace: monitoring
spec:
groups:
- name: hosts-system
rules:
- alert: 磁盘空间使用率告警
expr: 100
- (node_filesystem_avail_bytes{fstype=~"xfs|ext4",job="node_exporter"}
/ node_filesystem_size_bytes{fstype=~"xfs|ext4",job="node_exporter"}) * 100
> 90
for: 10m
labels:
severity: critical
opsalertname: 磁盘空间使用率告警
annotations:
summary: '磁盘使用率告警'
description: |
磁盘使用: {{ $labels.mountpoint }}分区磁盘使用率{{ $value | humanize }} %, 大于告警阈值90%
- alert: 服务器宕机告警
expr: up{job="node_exporter"} == 1 #正确应该为0,为了测试告警通知是否生效
for: 30s
labels:
severity: critical
opsalertname: 服务器宕机告警
annotations:
summary: '服务器宕机'
description: |
主机: {{ $labels.instance }}服务器宕机
- alert: 磁盘inode使用率告警
expr: 100 - (node_filesystem_files_free{job="node_exporter",fstype=~"ext4|xfs"} / node_filesystem_files{job="node_exporter",fstype=~"ext4|xfs"}) * 100 > 80
for: 15m
labels:
severity: critical
opsalertname: 磁盘inode使用率告警
annotations:
summary: "磁盘Inode告警"
description: |
Inode使用: {{ $value | humanize }} %, 大于告警阈值80%
- alert: 内存使用率告警
expr: 100 - ( node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes ) * 100 > 90 # 正常值为90,为了测试告警信息可以设置10%一个比较小的值测试下
for: 10s #正常值为5m
labels:
severity: critical
opsalertname: 内存使用率告警
annotations:
summary: '内存使用率告警'
description: |
内存使用率告警 {{ $value | humanize }} %, 大于告警阈值90%
Comments | NOTHING